想去🏃
字符串和格式化输入/输出
sizeof函数
C99 和 C11 标准专门为 sizeof 运算符的返回类型添加 了%zd 转换说明,这对于strlen()同样适用。对于早期的C,还要知道sizeof和 strlen()返回的实际类型(通常是unsigned或unsigned long)。
sizeof 使用圆括号使用时机否取决于运算对象是类型还是特定量?运算对象是类型时, 圆括号必不可少,但是对于特定量,可有可无。也就是说,对于类型,应写 成sizeof(char)或sizeof(float);对于特定量,可写成sizeof name或sizeof 6.28。 尽管如此,还是建议所有情况下都使用圆括号,如sizeof(6.28)。
C预处理器
#define NAME value
会替换代码中NAME为value 注意没有赋值语句
C90标准新增了const关键字,用于限定一个变量为只读
如 const int CXK_BALLS = 10;
const用起来 比#define更灵活
使用limits.h头文件可以查询系统int的最大值和最小值
INT_MAX和INT_MIN
float.h头文件中也定义一些明示常量,如FLT_DIG和 DBL_DIG,分别表示float类型和double类型的有效数字位数。
转换说明和各自对应的输出类型
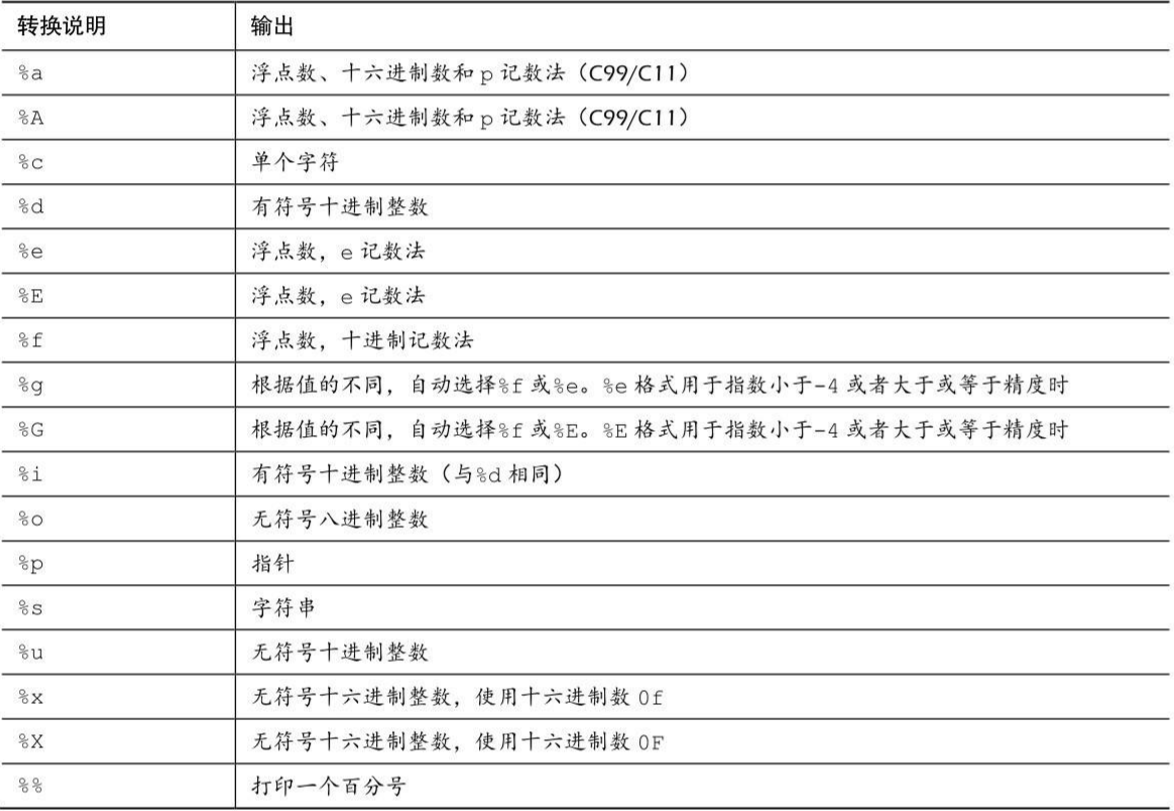
printf()的转换说明修饰符
字段宽度在打印整数
1 | const int PAGES = 959; |
结果为
1 | *959* |
第2个转换说明是%2d,其对应的输出结果应该是2字段宽度。因为待打印整数有3位数字,所以字段宽度自动扩大以符合整数的长度。
1 | printf("**%5d**%5.3d**%05d**%05.3d**\n", 6, 6, 6, 6); |
结果为
1 | ** 6** 006**00006** 006** |
使用精度(%5.3d)生成足够的前导0以满足最小位数的要求(本例是3)。然而,使用0标记会使得编译器用前导0填充满整个字段宽度。最后,如果0标记和精度一起出现,0标记会被忽略。
浮点型格式
1 | const double RENT = 3852.99; // const变量 |
输出的结果为:
1 | *3852.990000* |
+标记使得打印的值前面多了一个代数符号(+)。而0标记使得打印的值前面以0填充以满足字段要求。%010.2f的第1个0是标记,句点(.)之前、标记之后的数字(本例为10)是指定的字段宽度。
字符串格式
1 | #define BLURB "Authentic imitation!" |
结果为
1 | [Authentic imitation!] |
.5告诉printf()只打印5个字符,-标记使得文本左对齐输出。
转换不匹配
short int是2字节,char是1字节。当printf()使用%c打印short int336时,它只会查看储存336的2字节中的后1字节。这种截断相当于用一个整数除以256,只保留其余数。在这种情况下,余数是80,对应的ASCII值是字符P。用专业术语来说,该数字被解释成“以256为模”(modulo 256),即该数字除以256后取其余数。
1 | float n1 = 3.0; |
结果为
1 | 3.0e+00 3.0e+00 3.1e+46 1.7e+266 |
%e转换说明让printf()函数认为待打印的值是double类型(本系统中double为8字节)。当printf()查看n3(本系统中是4字节的值)时,除了查看n3的4字节外,还会 查看查看n3相邻的4字节,共8字节单元。接着,它将8字节单元中的位组合解释成浮点数(如,把一部分位组合解释成指数)。因此,即使n3的位数正确,根据%e转换说明和%ld转换说明解释出来的值也不同。最终得到的结果是无意义的值。
第3行输出显示,如果printf()语句有其他不匹配的地方,即使用对了转 换说明也会生成虚假的结果。用%ld转换说明打印浮点数会失败,但是在这 里,用%ld打印long类型的数竟然也失败了!问题出在C如何把信息传递给函
数。具体情况因编译器实现而异。
1 | printf("%ld %ld %ld %ld\n", n1, n2, n3, n4); |
该调用告诉计算机把变量n1、n2、n3和n4的值传递给程序。这是一种常见的参数传递方式。程序把传入的值放入被称为栈(stack)的内存区域。 计算机根据变量类型(不是根据转换说明)把这些值放入栈中。因此,n1被储存在栈中,占8字节(float类型被转换成double类型)。同样,n2也在栈中 占8字节,而n3和n4在栈中分别占4字节。然后,控制转到printf()函数。该函 数根据转换说明(不是根据变量类型)从栈中读取值。%ld转换说明表明 printf()应该读取4字节,所以printf()读取栈中的前4字节作为第1个值。这是 n1的前半部分,将被解释成一个long类型的整数。根据下一个%ld转换说 明,printf()再读取4字节,这是n1的后半部分,将被解释成第2个long类型的 整数(见图4.9)。类似地,根据第3个和第4个%ld,printf()读取n2的前半部 分和后半部分,并解释成两个long类型的整数。因此,对于n3和n4,虽然用 对了转换说明,但printf()还是读错了字节。
printf()的返回值
printf()函数返回打印字符的个数(包括空格和不可见的换行符(\n)),如果有输出错误,则返回一个负值(printf()的旧版本会返回不同的值)。
scanf()的返回值
scanf()函数返回成功读取的项数。如果没有读取任何项,且需要读取一个数字而用户却输入一个非数值字符串,scanf()便返回0。当scanf()检测 到“文件结尾”时,会返回EOF(EOF是stdio.h中定义的特殊值,通常用 #define指令把EOF定义为-1)。
scanf()函数允许把普通字符放在格式字符串中。除空格字符外的普通字 符必须与输入字符串严格匹配。
scanf()读取
空白字符(制表符、空格和换行符)在 scanf()处理输入时起着至关重要 的作用。除了%c 模式(读取下一个字符),scanf()在读取输入时会跳过非空白字符前的所有空白字符,然后一直读取字符,直至遇到空白字符或与正在读取字符不匹配的字符。考虑一下,如果scanf()根据不同的转换说明读取 相同的输入行,会发生什么情况。假设有如下输入行:
1 | -13.45e12# 0 |
如果其对应的转换说明是%d,scanf()会读取3个字符(-13)并停在小数 点处,小数点将被留在输入中作为下一次输入的首字符。如果其对应的转换 说明是%f,scanf()会读取-13.45e12,并停在#符号处,而#将被留在输入中作 为下一次输入的首字符;然后,scanf()把读取的字符序列-13.45e12转换成相应的浮点值,并储存在float类型的目标变量中。如果其对应的转换说明是%s,scanf()会读取-13.45e12#,并停在空格处,空格将被留在输入中作为下一次输入的首字符;然后,scanf()把这 10个字符的字符码储存在目标字符 数组中,并在末尾加上一个空字符。如果其对应的转换说明是%c,scanf() 只会读取并储存第1个字符,该例中是一个空格
scanf缓冲区
假如scanf(“%s”,name)时输入的名字包括了姓和名,如kio k,这时候由于scanf遇到空格就停止了,所以后面的k会被保存在缓冲区,下一次读取的时候会先读取这部分,假如下一次是scanf(“%f”,&weight)时就会报错,一直匹配不上float。另外如果输入名字的时候填入了“kio 55”,那么后面输入体重时也会把55当成体重值。
printf()和scanf()的*修饰符
printf()的*修饰符
如果你不想预先指定字段宽度,希望通过程序来指定,那么可以用*修饰符代替字段宽度。但还是要用一个参数告诉函数,字段宽度应该是多少。
1 | printf("The number is :%*d:\n", width, number); |
scanf()的*修饰符
scanf()中用法与此不同。把*放在%和转换字符之间时,会使得 scanf()跳过相应的输出项。
1 | printf("Please enter three integers:\n"); |
跳过两个整数,把第3个整数拷贝给n,在程序需要读取文件中特定列的内容时,这项跳过功能很有用。

kio0o0
如果可以做到不懂就问,做不到的事情就拒绝,或许可以活得更轻松点