求知若饥,虚心若愚
如果游戏开发过程中从来都没有考虑优化,那么结果往往是惨不忍睹的,一个正确的做法是,从一开始就把优化当成是游戏设计中的一部分。
移动平台的特点
移动平台的GPU架构有很大的不同,更专注于尽可能使用更小的带宽和功能(不过近几年性能提升了不少,虽然和pc还是差很远,毕竟功耗限制,不然个个都是大火炉)。
为了尽可能移除隐藏的表面,减少overdraw(一个像素被绘制多次) ,不同芯片的做法:
- PowerVR芯片(通常用于iOS设备和某些Android设备):基于瓦片的延迟渲染(Tiled-based Deferred Rendering, TBDR) 架构,把所有的渲染图像装入一个个瓦片中,再由硬件找到可见的片元,而只有这些片元可见才会执行片元着色器
- Adreno(高通的芯片)和Mali(ARM的芯片):使用Early-Z或相似的技术进行低精度的深度检测,来剔除那些不需要渲染的片元
- Tegra(英伟达的芯片)等:使用了传统的架构设计,overdraw更可能造成性能的瓶颈
iOS平台的硬件条件相对统一,可以参考(https://docs.unity3d.com/550/Documentation/Manual/iphone-Hardware.html ),而Andorid不同设备的硬件区别很大,单SOC就有高通、联发科、三星、华为海思(近几年还有游戏厂商专门优化某款机型)。
影响性能的因素
对于一个游戏来说,主要需要使用两种计算资源:CPU和GPU,他两相互合作来影响帧率和分辨率。其中CPU主要负责保证帧率,GPU主要负责分辨率相关的处理。因此,造成游戏性能瓶颈的主要原因有:
- CPU
- 过多的drawcall
- 复杂的脚本或物理模拟
- GPU
- 顶点处理
- 过多的顶点
- 过多的逐顶点计算
- 片元处理
- 过多的片元(即可能是分辨率造成,也可能是overdraw造成)
- 过多的逐片元计算
- 顶点处理
- 带宽
- 使用了尺寸很大且未压缩的纹理
- 分辨率过高的帧缓存
对于CPU,限制它的主要是每一帧中 draw call 的数目。调用绘制命令的时候,就会产生一个 draw call。每次调用时CPU都需要改变很多渲染状态的设置,非常费时。但主要是过多会导致CPU 把大部分时间都花费在提交drawcall上了,GPU在那干等跑不满资源。
其他造成CPU瓶颈的原因,如物理、布料模拟、蒙皮、粒子模拟等也是计算量很大的操作,但不在本书讨论范围。
对于GPU,它负责整个渲染流水线,因此GPU的性能瓶颈和需要处理的顶点数目、屏幕分辨率、显存等因素有关。相关优化策略可以从减少处理的数据规模、减少运算复杂度等方面入手。
- CPU优化
- 使用批处理技术减少drawcall数目
- GPU优化
- 减少需要处理的顶点数目
- 优化几何体
- 使用模型的LOD(Level of Detail)技术
- 使用遮挡剔除(Occlusion Culling)技术
- 减少需要处理的片元数目
- 控制绘制顺序(以降低overdraw)
- 警惕透明物体
- 减少实时光照(减少pass和drawcall)
- 减少计算复杂度
- 使用Shader的LOD(Level of Detail)技术
- 代码方面的优化
- 减少需要处理的顶点数目
- 节省内存带宽
- 减少纹理大小
- 利用分辨率缩放
Unity中的渲染分析工具
Unity内置分析工具有:
- 渲染统计窗口(Rendering Statistics Window)
- 性能分析器(Profiler)
- 帧调试器(Frame Debugger)
认识Unity5的渲染统计窗口
渲染统计窗口(Rendering Statistics Window)显示当前游戏各个渲染统计变量,可以通过Game视图右上方的菜单中单机Stats按钮来打开它,如下图所示:

| 信息名称 | 描述 |
|---|---|
| 音频 | 这里不讨论 |
| 每帧的时间和FPS | 处理和渲染一帧所需的时间,以及FPS |
| Batches | 一帧中需要进行的批处理数目 |
| Saved by batching | 合并的批处理数目,这个数字表明了批处理为我们节省了多少 draw call |
| Tris和Verts | 需要绘制的三角面片和顶点数目 |
| Screen | 屏幕的大小,以及它占用的内存大小 |
| SetPass | 渲染使用的Pass数目,每个Pass都需要Unity的runtime来绑定一个新的Shader,这可能造成CPU的瓶颈 |
| Visible skinned meshes | 渲染的蒙皮网格的数目 |
| Animations | 播放的动画数目 |
Unity5渲染统计窗口去掉了 draw call 的显示,可以用性能分析器查看。
性能分析器的渲染区域
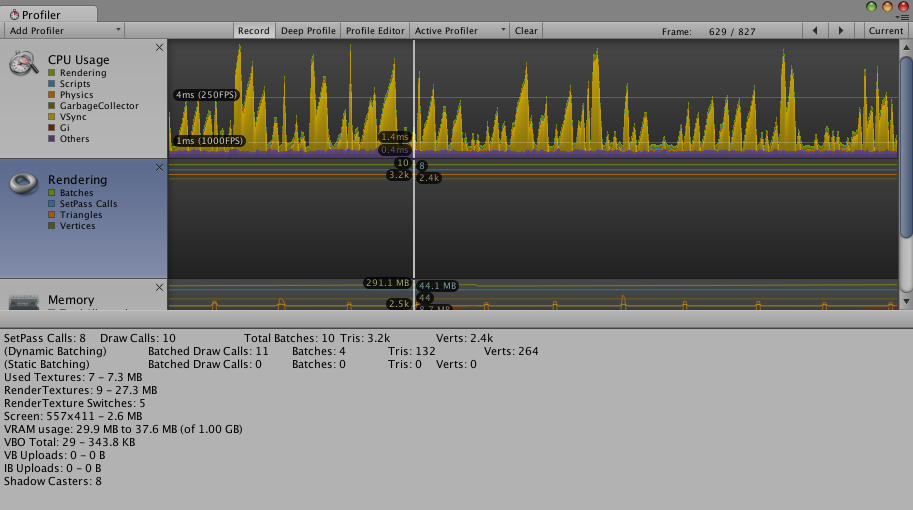
这里的数据会包含unity背后进行的工作数目,所以drawcall、pass数目等会多一点,可以用帧调试器详细查看
再谈帧调试器
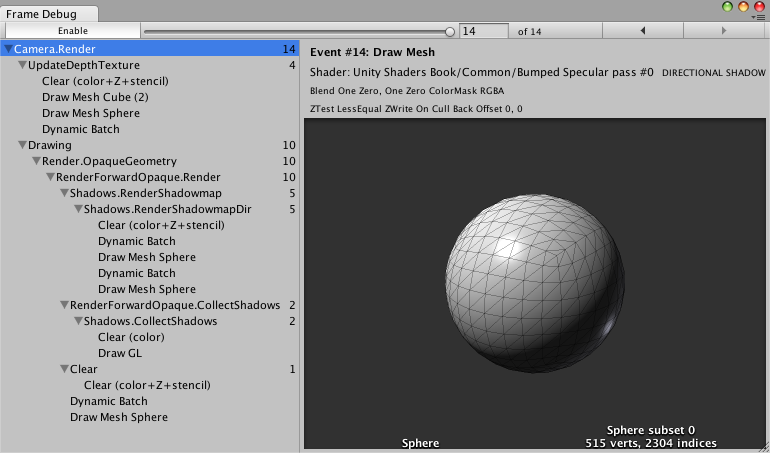
其他性能分析工具
对于移动平台上的游戏,我们更希望得到真机上运行游戏时的性能数据。
- Android
- 高通Adreno
- 英伟达NVPerfHUD
- iOS
- 内置分析器
- PowerVRAM的 PVRUniSCo shader 分析器
- XCode中的 OpenGL ES Driver Instruments
- 一些其他的性能分析工具可以在Unity的官方手册中找到:https://docs.unity3d.com/Manual/profiler-profiling-applications.html
- 除此之外,现在还有UPR可用来进行全平台的性能分析:https://upr.unity.cn/
减少drawcall数目
批处理(batching) ,实现原理是为了减少每一帧需要的 draw call 数目,每次调用 draw call 时尽可能的处理多个物体。
什么样的物体可以一起处理:使用同一个材质的物体,它们之间的不同仅仅在于顶点数据的差别。
Unity支持两种批处理方式:
- 动态批处理:优点是Unity自动完成,并且物体可移动。缺点是限制很多,一不小心就失效了。(需要考虑合批过程的消耗)
- 静态批处理:优点是自由度很高,限制很少。缺点是可能会占用更多的内存,而且经过静态批处理后的物体都不可以再移动了(包括脚本设置位置)。
动态批处理
如果场景中有一些模型共享了同一材质并满足一些条件,Unity自动把它们进行批处理,从而只需要花费一个drawcall就可以渲染这些模型。动态批处理的基本原理是,每一帧把可以进行批处理的模型网格进行合并,再把合并后的模型数据传递给GPU,然后使用同一个材质对其进行渲染。
需要满足条件:
- 顶点属性规模小于900,如果用了三个顶点属性(顶点位置、法线和纹理坐标),那么顶点数目就不能超过300了,这个数字未来可能会变化。
- 所有对象的需要使用同一个缩放尺度。但Unity5已经不限制这个了。
- 使用光照纹理(lightmap)的物体需要小心处理。为了让这些物体可以被动态批处理,需要保证它们指向光照纹理中的同一个位置(光照纹理中的索引、偏移量和缩放信息等)
- 多Pass的Shader会中断批处理。所以前向渲染中额外的逐像素光源会打断
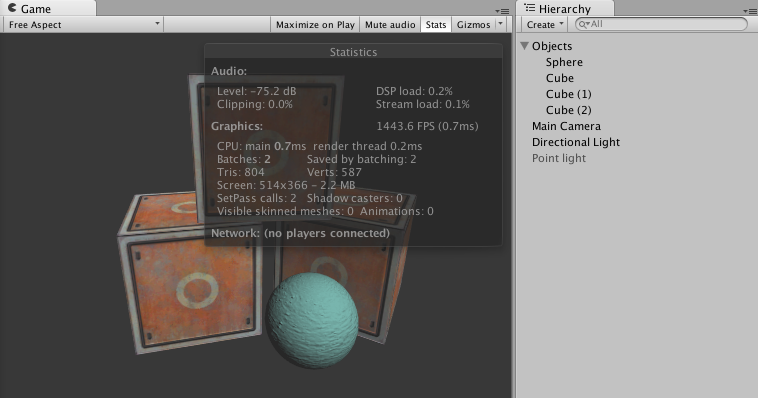
动态批处理
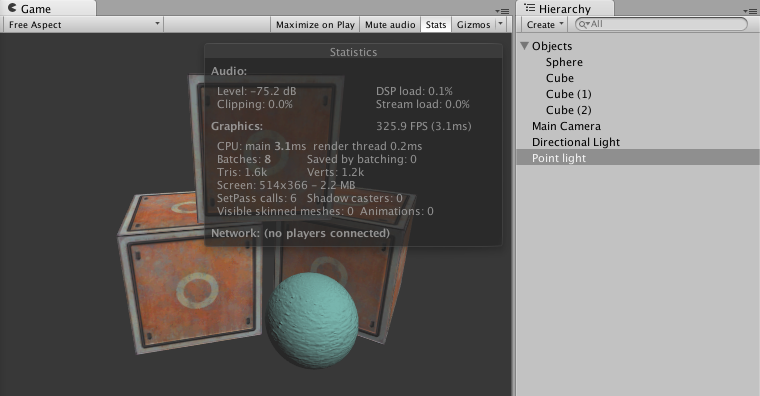
多光源对动态批处理的影响结果
可以用帧调试器查看为什么没有合批,Unity默认不会开启动态批处理,可在玩家设置那里修改。
静态批处理
相比动态批处理,静态批处理适用于任何大小的几何模型。实现原理是,只在运行开始阶段,把需要进行静态批处理的模型合并到一个新的网格结构中,这意味着这些模型不可以在运行时刻被移动。
它的缺点是往往需要更多的内存来存储合并后的几何结构。原因是如果在静态批处理前一些物体共享了相同的网格,那么在内存中每一个物体都会对应一个该网格的复制品,即一个网格会变成多个网格再发送给GPU。解决方法是要么忍受这种牺牲内存换取性能的方法,要么不用静态批处理改用动态批处理,或者自己编写批处理方法。
将物体面板上的Static复选框勾选上(实际上只需要Batching Static),就可以实现静态批处理。
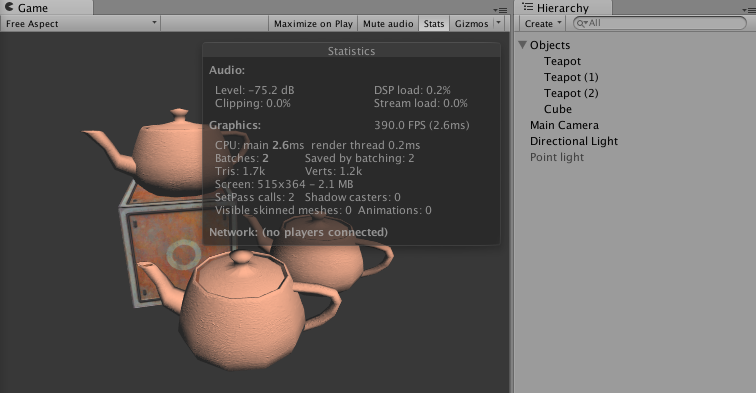
开启静态批处理
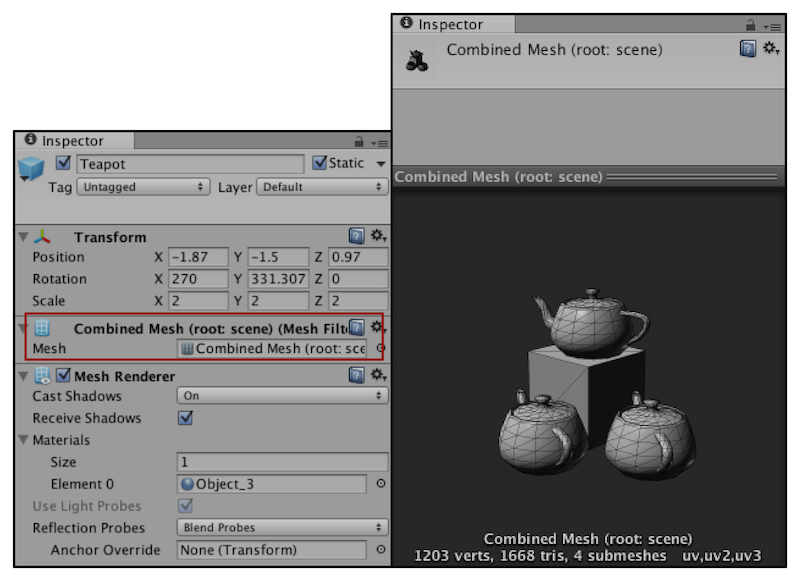
静态批处理中Unity会合并所有被标识为“Static”的物体

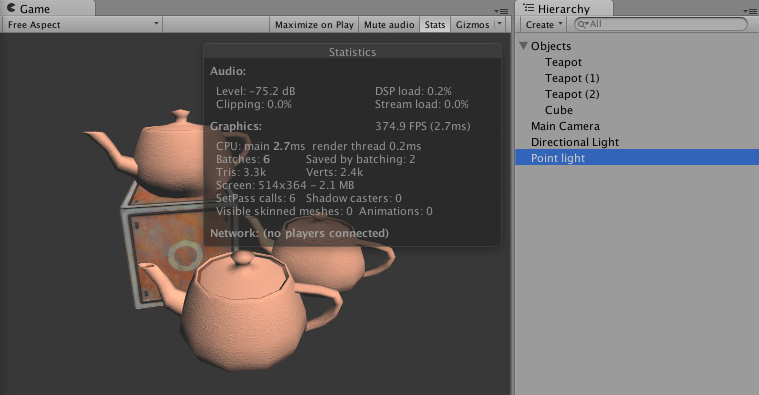
静态批处理会占用更多的内存。左图:静态批处理前的渲染统计数据。右图:静态批处理后的渲染统计数据
Unity首先把这些静态物体变换到世界空间下,然后为他们构建一个更大的顶点和索引缓存。对于使用了同一材质的物体,unity只需要调用一个draw call就可以绘制全部物体。而对于使用了不同材质的物体,静态批处理同样可以提升渲染性能。尽管这些物体仍然需要调用多个draw call,但静态批处理可以减少这些draw call之间的状态切换,而这些切换往往是费时的操作。从合并后的网格结构中发现,尽管3个水壶模型使用了同一个网格,但合并后却变成了3个独立网格。而且我们可以从unity的profiler观察到在应用静态批处理前后VBO total(Vertex Buffer Object,顶点缓冲对象)的变化,数目会变大,这正是因为静态批处理会占用更多内存的缘故。
我这个版本2021没有VBO相关数据,而且合并后的网格不包括正方体,不知道是metal 平台原因还是版本不同。
处理其他逐像素光的Pass不会被静态批处理
共享材质
以上知道了无论是动态批处理还是静态批处理,都要求模型之间材质相同。但不同模型之间总会有不同的渲染属性,例如纹理、颜色等。所以需要一些策略来尽可能合并材质:
- 如果只是纹理不同,可以把这些纹理合并到一张更大的纹理中,这个称为图集(atlas)。再使用不同的采样坐标对纹理采样。
- 除了纹理不同,还有其他微小的参数变换,例如颜色、某些浮点属性。一种常用的方法是使用网格的顶点数据来存储参数(顶点颜色)(MaterialPropertyBlock?)
如果要在脚本中访问共享材质,应使用 Renderer.sharedMaterial 来保证修改的是和其他物体共享的材质,而不是 Renderer.material(会生成一个副本,从而破坏批处理)。
批处理的注意事项
在选择使用动态批处理还是静态批处理时,建议:
- 尽可能选择静态批处理,但要时刻小心对内存的消耗,并且记住经过静态批处理的物体不可以再被移动。
- 如果无法进行静态批处理,而使用动态批处理,要小心它的条件限制。
- 对于游戏中的小道具,如可以拾取的金币等,可以使用动态批处理。
- 对于包含动画的物体,无法全部使用静态批处理,但其中如果有不动的部分,可以标识成 Static。
由于批处理需要把多个模型变换到世界空间下再合并它们,如果 Shader 中存在基于模型空间下的坐标运算,会得到错误的结果。一个解决方法是在 Shader 中使用 DisableBatching 标签来强制使该 Shader 的材质不会被批处理。
半透明材质通常需要使用严格的从后往前的绘制顺序来保证透明混合的正确,这些物体 Unity 会首先保证它们的绘制顺序,再尝试进行批处理。所以当绘制顺序无法满足时,批处理无法在这些物体上被成功应用。
减少需要处理的顶点数目
优化几何体
在建模时要记住:尽可能减少模型种三角面片的数目,一些对于模型没有影响、或是肉眼非常难察觉到区别的顶点都要尽可能去掉。很多三维建模软件都有自动优化网格结构的选项。
在Unity的渲染统计窗口,可以看到渲染当前帧需要的三角面片数目和顶点数目,往往是多于建模软件里显示的。这是因为三维软件中组成几何体的每个点就是单独的一个点,但在Unity中GPU看来,有时需要把一个顶点拆分成两个或更多的顶点。原因是 分离纹理坐标(uv splits) 和 产生平滑的边界(smoothing splits)。
另外,建议移除不必要的硬边以及纹理衔接,避免边界平滑和纹理分离。
模型的LOD技术
在 Unity 中使用 LOD Group 组件为物体构建 LOD。为同一个对象准备多个不同细节程度的模型,然后把它赋给 LOD Group 组件中的不同等级。Unity会自动判断当前位置上需要使用哪个等级的模型,来减少渲染面片数量。(太远的物体使用精细模型也看不出来,不如使用低模)
遮挡剔除技术
遮挡剔除(Occlusion culling):消除那些在其他物件后面看不到的物件,不会计算那些看不到的顶点,以提升性能。和相机的视锥体剔除(Frustum Culling)不同。
减少需要处理的片元数目
重点在于减少 overdraw,即同一个像素被绘制了多次。
在 Scene 视图左上方的下拉菜单中选中 Overdraw,切换成可以查看 overdraw 的视图,可以看物体相互遮挡的层数。
控制绘制顺序
控制绘制顺序可以最大限度地避免overdraw,由于深度测试的存在,我们可以保证物体都是从前往后绘制。
尽可能的把物体的队列设置为不透明物体(opaque)(如 Background Geometry AlphaTest)。避免使用半透明队列(Transparent Overlay),因为它们是从后往前绘制的。
我们还可以充分利用Unity 的渲染队列来控制绘制顺序。例如,在第一人称射击游戏中,对于游戏中的主要人物角色来说,他们使用的shader 往往比较复杂,但是,由于他们通常会挡住屏幕的很大一部分区域,因此我们可以先绘制它们(使用更小的渲染队列〉。而对于一些敌方角色,它们通常会出现在各种掩体后面,因此,我们可以在所有常规的不透明物体后面渲染它们(使用更大的渲染队列〉。而对于天空盒子来说, 它几乎覆盖了所有的像素,而且我们知道它本远会出现在所有物体的后面,因此, 它的队列可以设置为“ Geometry+ 1 ”。这样,就可以保证不会因为它而造成overdraw 。
时刻警惕透明物体
因为半透明对象没有开启深度写入,如果要正确渲染,必须从后往前。这意味着半透明物体几乎一定会造成 overdraw。GUI对象大多被设置成了半透明,如果屏幕中GUI占据的比例太多,而主相机有没有进行调整而是渲染整个屏幕,那么GUI就会造成大量overdraw。
对于占据屏幕多的半透明 GUI,可以尽量减少 GUI 所占面积。可以将把 GUI 的绘制和三维场景的绘制交给不同的相机,而其中负责三维场景的摄像机的视角范围尽量不要和GUI的相互重叠(感觉不是很美观)。
在移动平台上,透明度测试会影响性能,因为使用的 discard 或 clip 等操作,会导致一些硬件的优化策略失效,如 PowerVR 使用的基于瓦片的延迟渲染技术(会使得Early-Z失效?)。这时透明度混合的性能往往比透明度测试好。
减少实时光照和阴影
实时光照对于移动平台是一种非常昂贵的操作。因为对于逐像素的光源来说,被这些光源照亮的物体需要再被渲染一次,容易增加overdraw和drawcall,而且这些额外的pass不能进行批处理。
有这些方法,可以减少实时光照和阴影:
- 通过烘焙技术,将光照提前烘焙到一张光照纹理(lightmap)中,然后在运行时刻只需要根据纹理采样得到光照结果
- 使用 God Ray 模拟光源,不是真的光源,通过透明纹理模拟
- 一定要用更多的实时光的话,可以用逐顶点光照代替
- 把复杂光照计算存储到一张查找纹理(lookup texture,也被称为查找表,lookup table,LUT)。在运行时,使用光源方向、视角方向、法线方向等参数对 LUT 采样
- 使用烘焙把静态物体的阴影信息存储到光照纹理中,只对场景中的动态物体使用适当的实时阴影
节省带宽
大量使用未经压缩的纹理以及使用过大的分辨率,都会造成由于带宽而引发的性能瓶颈
减少纹理大小
- 所有纹理的长宽比最好是正方形,且长宽值最好是2的整数幂
- 使用多级渐远纹理技术(mipmapping),在距离物体很远时,会使用更小、更模糊的纹理来代替
- 纹理压缩,不同平台格式不同,Unity会自己选用
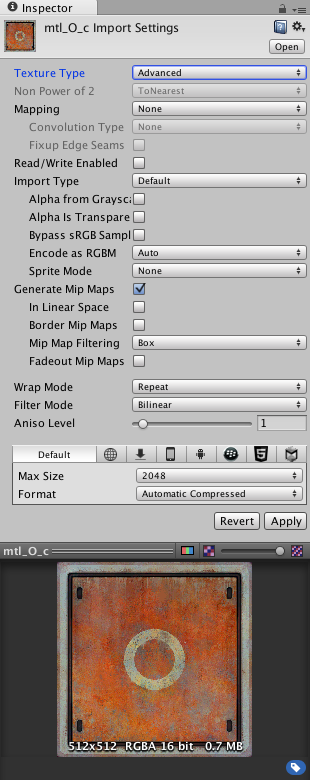
Unity的高级纹理设置面板
利用分辨率缩放
尤其对于很多低端手机,除了分辨率高其他硬件条件并不好。因此可能需要对于特定机器进行分辨率的缩放。
Unity 中设置屏幕分辨率可以直接调用 Screen.SetResolution
减少计算复杂度
Shader的LOD技术
和模型的 LOD 技术类似,Shader 的 LOD 技术可以控制使用的 Shader 等级,当 Shader 的 LOD 值小于某个设定的值,才会被使用:
1 | SubShader{ |
Shader 的默认 LOD 等级无限大,这意味着,任何被当前显卡支持的Shader 都可以被使用。但是,在某些情况下我们可能需要去掉一些使用了复杂计算的Shader 渲染。这时,我们可以使用 Shader.maximumLOD 或 Shader.globalMaximumLOD 来设置允许的最大LOD 值。
Unity 内置的Shader 使用了不同的LOD 值,例如,Diffuse 的LOD 为200 ,而Bumped Specular 的 LOD 为400 。
代码方面的优化
通常来说,游戏需要计算的数目排序是:对象数<顶点数<像素数。所以尽可能把计算提前
普遍成立的优化策略:
- 尽可能使用低精度的浮点值进行运算
- float/highp 适用于存储顶点坐标等
- half/mediump 适用于标量、纹理坐标
- fixed/lowp 适用于颜色变量和归一化的方向矢量。避免对低精度变量使用频繁的 swizzle 操作(如 color.xwxw)
- 避免不同精度之间的转换
- 使用插值寄存器把数据从顶点着色器传递到下一个阶段时,尽可能使用少的插值变量
- 少使用全屏的屏幕后处理效果。
代码优化规则
- 少用分支语句和循环语句
- 少用类似 sin/tan/pow/log 等较为复杂的数学运算,用查找表来替代
- 少用discard操作,会影响硬件的某些优化
根据硬件条件进行缩放
移动设备性能千差万别。
一个非常简单且使用的方式是放缩(scaling)思想。先保证游戏最基本的配置在所有平台上运行良好,对于更好的设备,可以使用更高的分辨率、开启屏幕后处理、粒子效果等。
扩展阅读
- Unity官方手册的移动平台优化实践指南,针对移动平台的优化技术,包括渲染和图形方面的优化,脚本优化等:https://docs.unity3d.com/Manual/MobileOptimizationPracticalGuide.html
- 优化图像性能:https://docs.unity3d.com/Manual/OptimizingGraphicsPerformance.html
- SIGGRAPH 2011 上 Unity 进行了一个关于移动平台上Shader优化的演讲:https://blogs.unity3d.com/2011/08/18/fast-mobile-shaders-talk-at-siggraph/
- Unite 2013,Unity 一个名为针对移动平台优化的演讲
- GDC 2014,Unity 展示了如何使用内置的分析器分析移动平台的游戏性能
- SIGGRAPH 2015,Unity 进行了一系列的演讲
- Unity 和来自高通、ARM等公司的开发人员共同呈现了名为 Moving Mobile Graphics 的课程中,讲解了移动平台上 PBR 的优化技术
- 2011年发布在移动平台的第三人称射击游戏《ShadowGun》
- Unity 自带的项目《Angry Bots》
- Unity3D研究院之使用Android的硬件缩放技术优化执行效率 http://www.xuanyusong.com/archives/3205

kio0o0
如果可以做到不懂就问,做不到的事情就拒绝,或许可以活得更轻松点