性能总览与瓶颈定位
优化方向
- 先优化iOS,再优化Android(iOS分析工具齐全,以及机型少、系统统一)
- 先共性性能优化,再兼容性方面的性能优化
常用工具
- Profiler
- Frame Debugger
- Memory Profiler
- Profile Analyzer
- UPR 工具
- NsightGraphics
- Xcode(十分强大)
瓶颈定位
通过Profiler工具


- 初步观察示例项目,发现Gfx.WaitForPresentOnGfxThread占用比较高
- 这是主线程在等待渲染线程完成工作
- 这种情况一般是GPU瓶颈或者CPU与GPU的带宽阻塞
- 同时观察Timeline,查看一帧中渲染进程谁占用比较高
- 这里是PostProcess进程,但也不能武断判断他就是渲染瓶颈,需要尝试手动屏蔽
Unity常见的等待函数
| 等待函数 | 功能 |
|---|---|
| WaitForTargetFPS | 等待达到目标帧率,一般这种情况CPU与GPU都没什么负载问题 |
| Gfx.WaitForGfxCommandsFromMainThread/WaitForCommand | 渲染线程己经准备接受新的渲染命令,一般瓶颈在CPU |
| Gfx.WaitForPresentOnGfxThread/WaitForPresent | 主线程等待渲染线程绘制完成,一般瓶颈在GPU |
| WaitForJobGroupID | 等待工作线程完成,一般瓶颈在CPU |
GPU或带宽瓶颈型游戏优化
- 渲染流程与效果优化
- 渲染中生成资源优化
- DrawCall与SetPassCall
- 片元着色器
- 渲染三角形
记录结果很重要
- 需要记录优化前的报告
- 从而对比优化后的成果
- 不然没有说服力
渲染流程分析
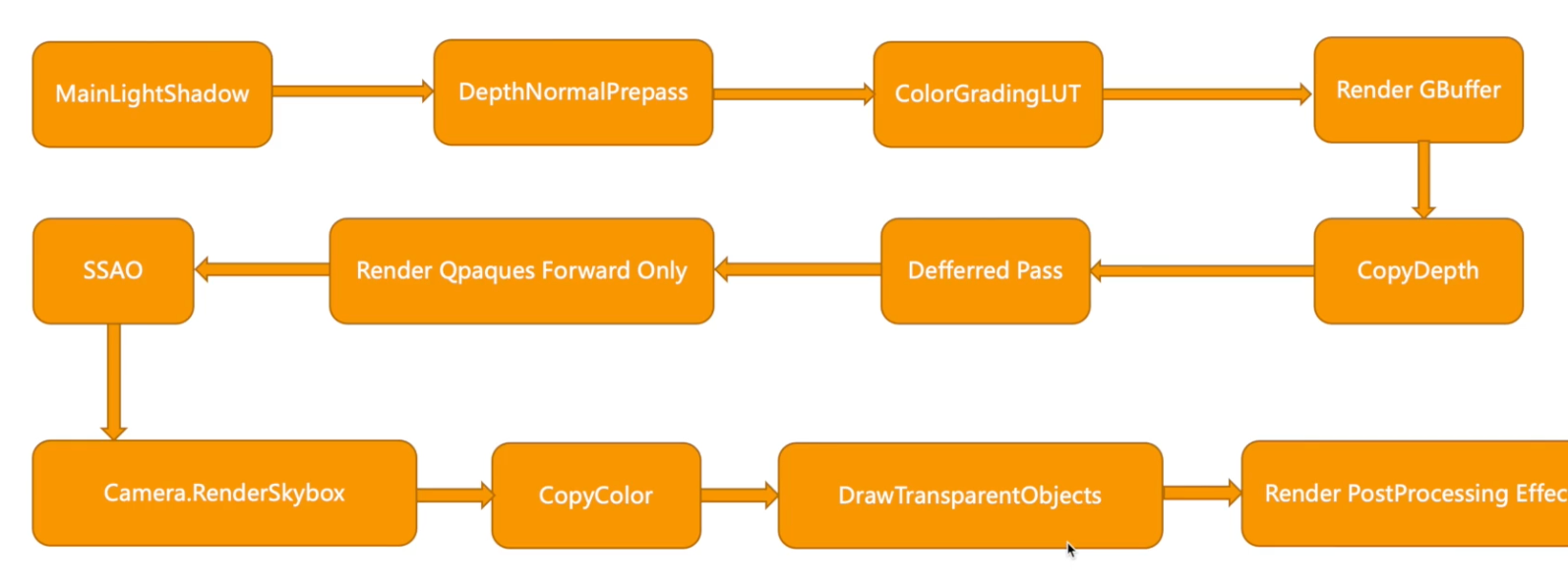
通过Frame Debug查看主要渲染流程,以下是课程项目中的渲染流程
Xcode Metal Capture
需要在Scheme中Option选项开启Gpu Frame Capture
- 提供十分强大的分析工具,包括各种资源使用情况,当前线程开启情况等
- 还可以抓帧分析,每帧所有指令的耗时以及渲染流程清晰可见
- 经验:任何超过1ms的渲染步骤都值得关注,尽量将GPU耗时控制在10ms
- Xcode工具会将有问题的流程标上三角叹号
- 该工具每个指令还提供:
- Attachments
- Geometry
- Bound Resources,当前使用的资源
- All Resources,整体使用的资源
- Pipeline Statisitics,渲染管线分析
- Performance,渲染性能分析
- CallStack,渲染api回调
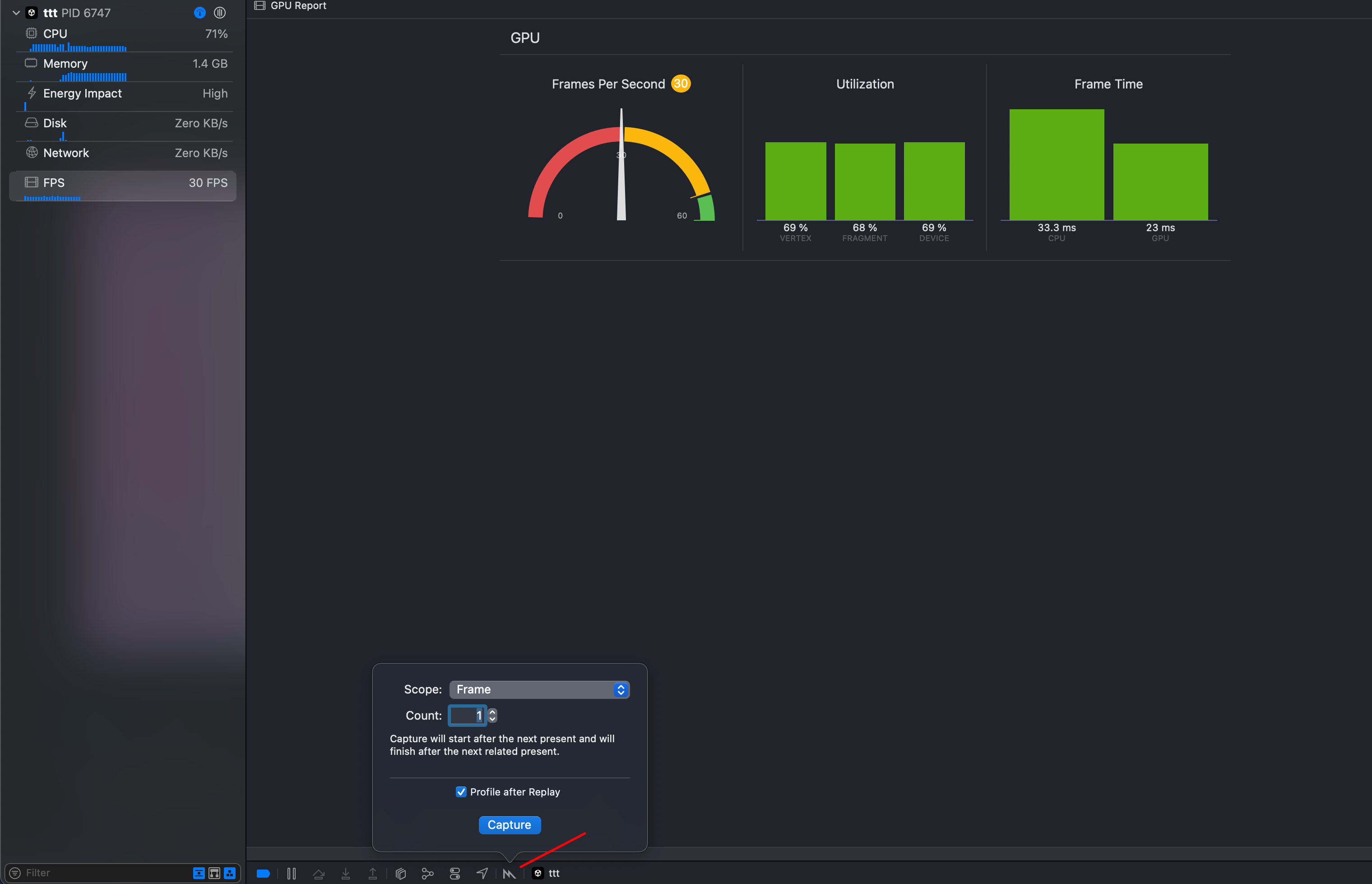
与设备分辨率相关的GPU开销优化
SSAO优化
- 通过Xcode Metal Capture查看SSAO第一个pass耗时十分多
- 查看其引用的资源,发现使用的纹理分辨率非常高,容易造成gpu采样瓶颈和带宽瓶颈
- 查看渲染管线分析,主要耗时在ALU time和Wait time,基本证实片元着色器片元压力大以及带宽瓶颈
- 查看性能分析,主要问题还是片元指令,片元指令过多以及缓存命中率低
- Timeline和Counters可以看到带宽读写、顶点与片元占用率、ALU逻辑单元运行、Cache缓存命中率等情况
- 主要优化:
- 降采样中间纹理,可修改srp源码对中间模糊纹理也降采样
- 将ao执行挪到不透明物体pass后面,提高移动端tbdr效率
- 适当调低ssao采样半径选项
- 采样次数,越低越好
- 改进ao图像模糊算法(单pass或其他算法),或者直接不使用(降分辨率本身就是一种模糊)
- 进一步优化:
- 使用hbao、gtao 方案
- 针对SSAO的Shader指令做进一步优化
- 采样烘焙AO到光照贴图的方案替换SSAO
- 优化后总耗时降低比ssao降低秒数还多:
- 填充率提高了
- SSAO 的占用资源减少之后,减少了其它环节的阻塞
- 缓存命中提高了
AA优化
反走样方案的发展
- 第一代:SSAA(超级采样抗锯齿Super-Sampling Anti-Aliasing )
- 第二代:(URP目前主要方案)
- MSAA(多重采样抗锯齿 Multi Sampling Anti-Aliasing)
- FXAA(快速近似抗锯齿Fast Approximate Anti-Aliasing)
- SMAA(增强子像素形变抗锯齿Enhanced Subpixel Morphological Anti-Aliasing )
- 第三代:TAA(时间序列抗锯齿Temporal Anti-Aliasing),目前还没有接入URP,可以使用PPV2包,但是不支持urp的motion vector,鬼影会比较严重
- 第四代:DLSS(基于深度学习的超级采样Deep Learning super Sampling ),需要特殊硬件支持,目前只有hdrp的pc平台(康康fsr)
注:这里只列出了Unity反走样的一些发展流程,其他反走样方案这里不包括
URP中的AA方案
| 方案 | URP支持 | 优点 | 缺点 |
|---|---|---|---|
| MSAA | URP默认支持,适合绝大多数非延迟渲染游戏 | 显卡硬件支持,反走样效果较好 | 仅支持前向渲,静态画面表现最好,运动画面一般,支持MRT的情况下效率较差,只能消除Geometry的反走样,对于高光像素部分无能为力 |
| FXAA | URP默认支持,有Quality与Console两个不同版本,Quality版本需要PPV2.适合一些对低端硬件有要求、对画面模糊不敏感的特殊游戏 | 后处理支持开销非常小,适合移动端 | 没有格外像素辅助,在高频颜色变化快的地方,动态场景会出现闪烁,对图形所有颜色边缘进行柔化处理 ,导致画面整体较模糊 |
| SMAA | URP默认支持,适合一些对低端硬件有要求的特殊游戏 | 后处理支持,开销相对较小,适合低端PC端 | 没有格外像素辅助 ,在高频颜色变化快的地方,动态场景会出现闪烁,三次pass,开销相对FXAA高一些,切换RT开销在手机上可能造成开销,边缘处理比FXAA精细些,但依然有模糊表现 |
| TAA | URP末来支持,可用PPV2扩展支持 | 支持延迟渲染,反走样效果较好,性能开销较小 | 动态场景下,低帧率下可能出现鬼影,无法处理半透明物体、贴图序列帧动画物体,需要额外内存开销,需要MotionVector Buffer |
效率:FXAA>SMAA>TAA>MSXX
质量:MSAA>SMAA>TAA>FXAA(这里的TAA支持并不完整在urp中)
优化手段
- 调低SMAA的质量选项
- 优化SMAA中间pass的中间纹理带宽开销,利用metal片上内存,修改为memoryless模式、以及storeaction
- 使用FXAA代替,有几毫米改进
- 评估是否需要AA,手机DPI较大,色彩跳动较下
优化示例工程AA方案总结
- 高端移动设备上采用优化后的SMAA或FXAA, Unity默认URP
下的TAA成熟后,根据性能与表现均衡选择采用 - 中端移动设备上采用FXAA方式或关闭AA渲染
- 低端移动设备上关闭AA渲染
PostProcess后处理优化
Unity URP下支持的后处理效果分类
- 色彩校正与增强(一般开销较低,但不可胡乱堆砌)
- Channel Mixer
- Color Adjustment
- Color Curves
- Lift,Gamma and Gain
- Shadows/Midtones/Highlights
- Tonemapping
- White Balance
- Split Toning
- 画面效果增强(一般需要额外PASS,涉及RT切换和采样,开销一般较高。建议使用local volume视条件开启)
- Bloom
- Chromatic Aberration
- Depth Of Field
- Film Grain
- Motion Blur
- 镜头效果(开销中等,主要是shader计算,建议视情况开启而不要全局)
- Lens Disortion
- Panini Projection
- Vignette
- Lens Flare
Unity URP下支持的后处理效果列表
| 效果列表 | 描述 | 移动端性能开销 | 常用性 | 优化方式 |
|---|---|---|---|---|
| Bloom | 泛光、镜头污垢 | 中高 | 高 | 降采样、降低迭代次数、替换2遍模糊pass算法(ue有提出移动端的优化手段)。 |
| Channel Mixer | 通道混合器 | 非常低 | 低 | 几乎无 |
| Chromatic Aberration | 散色像差,用于模拟相机的镜头无法将颜色聚合在一起的颜色失真效果(机器人视觉、屏幕破碎) | 中低(需要三遍采样) | 低 | 几乎无 |
| Color Adiustment | 颜色调整 | 中 | 高 | ColorGradingMode(HDR or LDR),如果支持浮点精度计算的平台或设备,HDR模式效率会更高 |
| Color Curves | 颜色曲线 | 低 | 低 | 几乎无 |
| Depth Of Field | 景深 | 非常高 | 中低 | 切换Gaussian与Bokeh的景深模式,移动平台建议用Gaussian |
| Film Grain | 胶片颗粒 | 中(需要采样多张Lookup纹理,可以修改LUT纹理大小) | 低 | 几乎无 |
| Lens Disortion | 镜头失真 | 中低 | 低 | 几乎无 |
| Lift, Gamma,and Gain | 提升、伽马与增益 | 非常低 | 低 | 几乎无 |
| Motion Blur | 运动模糊 | 高(需要MotionVector) | 中低 | MotionBlur质量分级、Intensity强度、Clamp摄像机旋转产生的速度可以具有的最大长度 |
| Panini Projection | Panini投影 | 中 | 低 | 几乎无 |
| Shadows、Midtones、Highlights | 阴影、中间调与高光 | 中低 | 低 | 几乎无 |
| Split Toning | 拆分着色 | 非常低 | 低 | 几乎无 |
| Tonemapping | 色调映射 | 中 | 中 | 几乎无 |
| Vignette | 渐晕,四边暗角,一般用于无ui动画或截图 | 中 | 低 | Intensity与Smoothness |
| White Balance | 白平衡 | 中低 | 低 | 几乎无 |
| Lens Flare | 镜头光晕 | 中高 | 中 | Occlusion设置与光晕数量 |
优化手段
- 去除不需要的后处理效果(最好是移除,不勾选复选框也会绑定资源,造成内存浪费)
- 有优化空间的后处理效果看上表
- 尽量不要全局使用volume效果
与场景复杂度相关的GPU开销优化
先从整体开销判断是不是场景复杂度瓶颈,一般看前向渲染(如果延迟渲染可以看阴影开销)各个阶段的DrawCall
条件允许优先做Simplization,接着Culling,最后才是Batching
常用观察数据
- Batches drawcall数量
- Tris 三角形数
- Verts 顶点数
- setpass calls
- shadowcasters 投影体数量
Simplization简化
场景简化总览
- 用编辑器的线框模式查看顶点和三角形分别情况
- 使用Rendering Debug 查看overdraw信息
- 使用Rendering Debug 查看级联阴影设置情况
地形分类
| 场景 | 描述 |
|---|---|
| 远景 | 视距较远,主要用于表现开阔景物,为了渲染总体气氛和空间感,配合景深使层次感更丰富,增加整体意境,一般不需要具体细节表现 |
| 中景 | 画面视觉中心的部分,进一步烘托场景气氛,需要一定视觉和细节表现,但不需要过分强调,更多通过材质颜色、质地、大范围光影明暗来呈现 |
| 近景 | 视距最近的画面部分,突出表现具体某个物体或角色上,需要突出表现材质细节,凹凸、光影细节、反射折射投射等,通过近景与中景远景的占比更好突出场景透视感 |
可以通过LOD来配合远中近景使用,一般层级不宜超过5级(原模型-简化1-简化2-替代体-剔除),不需要替代体的一般是4级,如果只在近景可见那就是两级了(原模型-剔除)
远景简化
远景不可达地形使用天空盒烘焙,而不用真实网格
- 反射探针烘焙cubemap
- legacy->cubemap(旧的方法,unity可能会舍弃)
- Camera.RenderToCubemap
中景简化
- 配合overdraw视图进行LOD简化,使用DCC软件制作或者Unity插件
- UnityMeshSimplifier简化Mesh
- 替代体生成Amplify Imposters与Runtime Imposters
- 要小心Quality setting中的LOD Bias
- 对一些简化后的LOD层级物体去除阴影投影,减少投影体数量
- 对一些静态光照物体,已经处于阴影体内也不必要开启投影体,视项目而定,毕竟可以开启SSAO弥补下
Culling剔除
遮挡剔除与灯关剔除
遮挡剔除Occlusion Culling是在CPU端做的优化,GPU可以通过延迟渲染、前向渲染配合EarlyZ|PreZ进行优化
- 需要在对应相机开启Occlusion Culling选项
- 对场景中设置成静态遮挡体或被遮挡体起作用
- 对应动态物体,比如门窗,可以通过添加Occlusion Portal 组件
- 注意需要烘焙场景,可以设置烘焙精度
对于不需要向其他物体投影的物体可以关闭投影选项(比如平坦的地形)
灯关方面的剔除
- 充分利用tbdr、forward+架构
- 前期注意使用urp的light layer功能
- 如果后期无法大量修改资源了,也可以通过脚本来控制灯光的开启
- 调整Quality urp setting中的灯光设置
- 主光源阴影贴图分辨率
- 每个对象最多受光源数量
- 额外光源的shadow Atlas resolution大小(这个是所有额外光源共享的纹理)
- 调整Quality urp setting中的级联阴影设置
Batching合批
不支持SRP Batcher的物体最好放在不透明渲染队列最后面,避免打断其他合批
Terrain优化
内置Terrain方案在移动端性能并不高,特别是shader不够轻量。
自己写一套地形烘焙工具
- 根据Terrain Data将mesh信息与混合后的地形纹理烘焙出来
- 再通过prefab生成地形块
- Unity商店也有挺多现成工具:Terrain To Mesh
烘焙完网格需要重新Occlusion Culling
如果是平坦地形,不需要自我投影时,请关闭投影选项
主光源级联阴影优化
- 减少级联层级
- 如果阴影变化不大,没有相关动画,可以将阴影进行缓存,按级联阴影的不同层级定制刷新频率,也是一种LOD思路(相关链接)
- 调整阴影的创建和销毁时机
- 去除渲染目标每帧清空逻辑
- 调整阴影刷新频率
渲染管线精简与优化
这块需要的知识面比较深,需要多回顾下https://www.bilibili.com/video/BV1i94y1Q7W3
引擎为了通用考虑,通常会有冗余的流程或资源生成,当项目需要深度优化时,进行管线的精简与优化是有必要的,高效的管线一定是定制化而非通用化的。
- unity通常需要做加法,因为其管线功能并没有那么强,需要添加新功能或替换已有效率不高的功能
- unreal通常需要做减法,因为其管线功能并不一定全需要用到,但其设置和流程与编辑器耦合比较紧密
- unity最佳实践还是需要写一套能满足表现需求,又无过多冗余流程的srp管线
主要手段
- 使用URP的Native RenderPass,主要是能优化一些需要多PASS的渲染效果(比如延时渲染需要gbuffer生成和着色两个pass,可以优化成一个native pass),主要目的是减少RT切换和读取的开销(节省带宽和内存,使用后Memoryless、load action为dontcare),使tbr架构更高效渲染。需要图形API支持(metal和vulkan)
- 去除URP为了通用且对于该项目冗余的PASS(绑定了资源又不使用的PASS),需要修改URP源码
- 考虑是否需要Normal与Depth提前生成的PASS,如果是延迟渲染则是可以不需要的,但一些透明物体又确实是前向渲染(URP 使用unlit着色器对象也会被强制使用前向渲染)。
- 如果开启SSAO发现即使使用了延迟渲染也会生成这个上述Normal、Depth PrePass,需要修改URP源码处理没有额外使用前向渲染不透明物体时不生成这个Pass的情况。(关键字ConfigureInput)
- 但去除这个pass可能会发现ssao不生效了,原因在于没有正确读取gbuffer中的法线与深度信息,可以将其资源绑定一下,但同时也会打断Native RenderPass了,需要权衡一下。
- 建议CopyDepth和CopyColor不要在URP设置中开启,而是使用对应相机设置覆写开启,可以将生成纹理生命周期控制在对应功能开启时,而不是实时生成
- 考虑是否需要CopyDepth(常用于深度雾、扫描线等效果)Pass,生成的深度图不能降采样
- 考虑是否需要CopyColor(常用于扰动、反射、UI上的效果)Pass,生成的颜色图可以降采样,但反射其实可以用SSR或反射探针实现,其他情况可以视条件开启,不需要全程使用
- Metal Api下延迟渲染管线除非开启了Native RenderPass否则都会进行CopyDepth(2021 URP)
- 修改URP源码需要将Library中的PackageCache对应的包拷贝到Packages中,后续如果URP要升级只能手动Merge代码
Shader指令优化
如果要按渲染功能分级优化:Shader LOD
Xcode查看Shader总体耗时排名:抓帧后将Group by API Call -> Group by Pipeline State
直接在Xcode抓帧中修改Shader后刷新即可看到修改变化
Shader四类性能指标
- ALU: GPU逻辑处理单元的时间花费
- Float指令占比过高时:浮点精度修改半浮点精度
- Complex过高时:减少sqrt、sin、cos、recip等复杂指令的使用
- Memory: 代表访问程序的一些缓冲区或纹理内存的时间花费
- Sample过高时:纹理降采样
- Load/Store过高时:降低分辨率或减少内存读写开销
- Control Flow:着色器在分支、循环、增量、跳转等指令上花费的时间。
- 使用恒定的迭代记数来最小化循环时间
- 使用一些指令替换或优化分支语句
- Syuchrouization: 在指令执行前等待所需系统资源或同步事件所花费的时间
- wait Memory:等待内存访问,如纹理采样或缓冲区读写Memory类的优化同样会改善此类同步问题
- wait Pixel:等待像素资源释放,除ColorAttachment外这些像素还来自深度与模版缓冲区或者用户自定义资源,Blender是造成像素等待的常见情况,合理的光栅化对象顺序(渲染排序)来减少等待时间
- Wait Barriar:等待同一组中其余线程完成,合理的compute shader group分组与线程分组可以改善这一情况
- Wait Atomic:等待原语指令同步,很难优化
Shader数据类型精度
- Float(32bit)(位置与纹理坐标信息时使用)
- Half(16bit)(纹理坐标与颜色信息时使用)
- Fixed(11bit)(颜色信息)(SRP下已不支持)
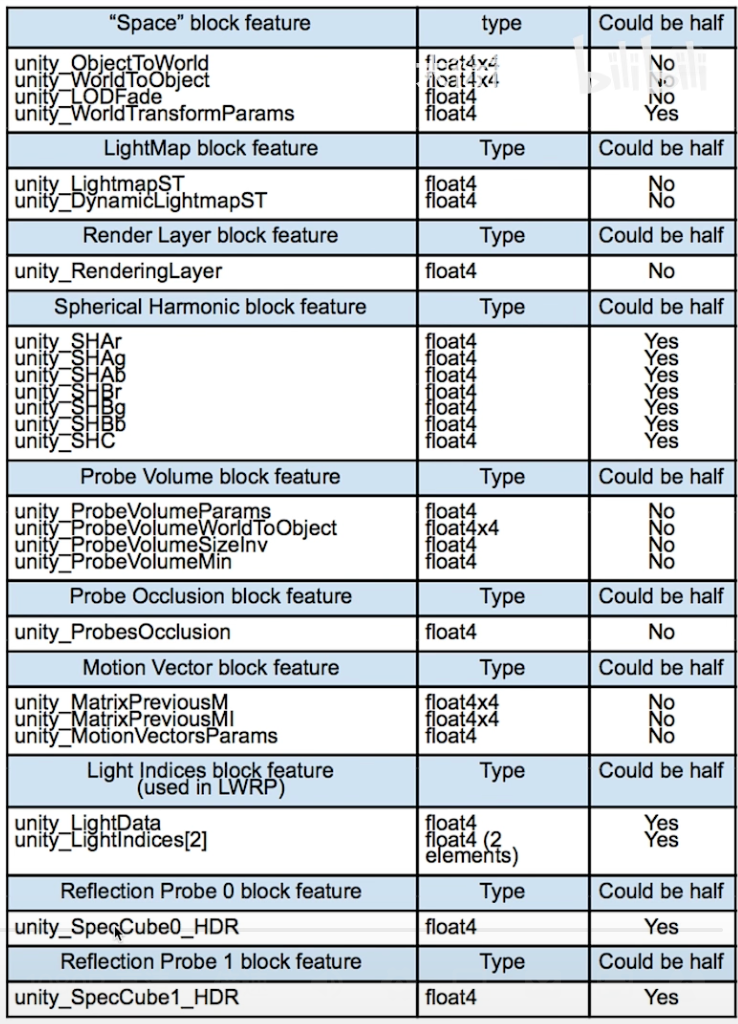
尽量使用内置函数
不要自己造轮子,内置函数有ALU单元优化
- pow
- normalize
- dot
- inversesqrt
- …
超越函数
一些变量之间关系不能用有限次加减乘除、乘方、开方运算表示的函数,这些函数在芯片上计算属于资源密集型函数,在低端设备上要慎用少用
- exp
- log
- sin,cos,tan…
- asin,acos,atan,atan2…
- sincos
- …
指令周期与阶段
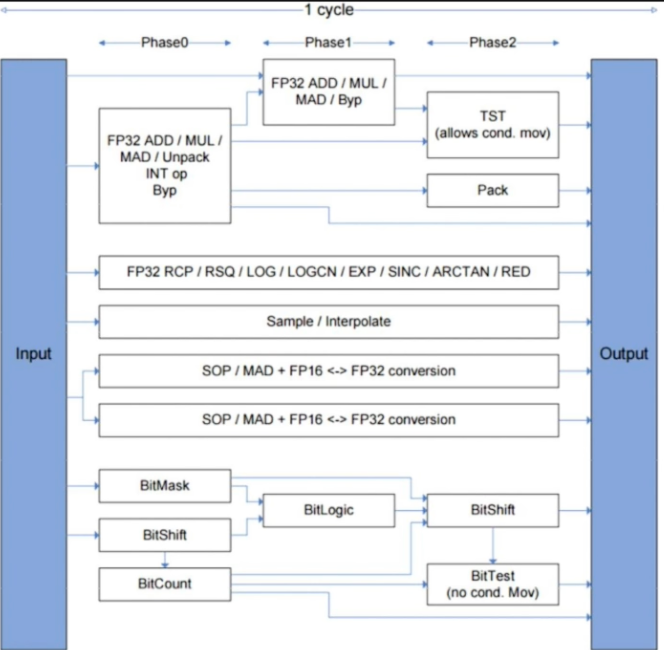
指令优化
- mul + add => mad
- (x-0.5)*1.5 -> ×*1.5+(-0.75)
- 除法 => rcp
- (t.x * t.y + t.z) / t.x -> t.y + t.z * ( 1.0 / t.x )
- 对齐
- float3 * float * float * float3 -> (float*float) * (float3*float3)
- abs或neg指令输出 => 输入
- abs(a.x * a.y) -> abs(a.x) * abs(a.y)
- -(a.x*a.y) -> -a.× * a.y
- saturate指令输入 => 输出
- 1.0-saturate(a) -> saturate(1.0-a)
- min或max => saturate (某些平合)
- max(x, 0.0) = min (x, 1.0) -> saturate (x)
- sart (×) = rcp (rsqrt (x)) : map to HW
- if0=>sign(×) if/else=>step(×) lerp (a, b, step (cx, cy));
- sin/cos/sincos << asin/acos/atan/atan2/degrees/radians
- mul(v.m) v.x*m[0] +v.y*m[1] + v.z*m[2] + v.w*m[3] : MAD-MAD-MAD
- mul(float4(v.xyz, 1)) v.×*m[0] + v.y*m [1] + v.z*m [2] + m[3] : MUL-MAD-MAD-MAD
- v.x*m[01 + (v.y*m[1]+(v.z*m|2] + m[3])) : MUL-MAD-MAD-ADD
- normalize/length/distance都包含一个dot,可以共亨,length(a-b)与distance(a,b)可共享,但与distance(b,a)不共享
- normalize (vec) = vec * rsart(dot (vec, vec) ) ; 50*normalize (vec) -> vec(50 * rsqrt(dot(vec, vec)))
- 自表达式不共享指令
- if(length(v) > 1.0)
- V = normalize (v)
- return v
- mul => mul24(高版本用于向量前三个相乘)
- fma 注重精度的mad
- texture.Load VS texture.Sample, Load (tc, offset) > Samole (tc, offset)
- FS=>VS,均衡GPU着色器负载
- 避免隐式转换,Vector4转成Vector3
- Varying数据尽可能组织成向量形式,而非标量,从而减少MissCache
其他指令优化
- [branch]UNITY_BRANCH :真分支是否动态判断,语句比较多,且大概率走其中某一条分支
- [flatten]UNITY_FLATTEN :分支是否展开,分支语句比较简单的情况,比如少于6条语句的分支
- [loop] UNITY_LOOP :循环语句不展开,标记为真循环
- [unroll] UNITY_UNROLL :循环语句展开
- [unroll(_x)] UNITY_UNROLL (_x) :循环语句展开到第几层
Early-z失效
- 开启Alpha Test
- Clip()
- Discard
- Alpha Coverage
- 光栅化后修改深度
- 手动关闭Depth Test
某些平台慎用或推荐用某些内置功能
- Alpha Test,需要真机测验
- Color Mask,需要真机测验
- sRGB硬件解压,大多数平台推荐用
内存优化
Unity中的内存概述与工具方法
| Unity中的内存 | 描述 |
|---|---|
| 托管内存 | 主要是指使用托管堆或者垃圾收集器自动分配和管理的内存也包括脚本堆栈与虚拟机内存(unity目前使用的贝母垃圾回收器比较保守) |
| C#非托管内存 | 可以在C#下与Unity Collection名字空间和包结合使用,不使用垃圾收集器管理的内存部分 |
| Native内存 | Unity用于运行引擎的C++内存 |
Unity应用程序的内存主要有:
- Unity中的内存
- 托管内存
- C#非托管内存
- Native内存
- 显存
- 其他内存
- 应用程序框架
- 第三方库
- 系统内存
内存工具:
- Profiler的内存分页,可以添加自定义memory module
- Memory Profiler:抓取内存快照
- UPR工具内存页
- Xcode-Profile-Allocations(可以看非Unity内存部分),VM Tracker需要勾选Automatic Snapshoting
- Dirty Size:不能被复用或卸载的内存块,比较重要,超过上限iOS程序会退出
- Swapped Size:不活跃的内存,可以被交换到磁盘上的大小
- Resident Size:使用的物理内存量
- Allocations-Call Tree-按线程分类,可以查看指定时间内某线程分配内存的堆栈情况
Unity中Allocator详解
对内存分配的封装分配器,用来拓展内存统计、检查和管理
Memory Setting:https://docs.unity3d.com/cn/current/Manual/performance-garbage-collection-best-practices.html
按用途分类
- Main Allocators:绝大数内存分配,主线程渲染资源相关、文件cache、typetree等不同用途下的分配器
- Fast Per Thread Temporary Allocators:线程上使用的临时分配器,包括各工作线程使用的栈分配器,比如音乐、渲染、预加载、烘焙等工作线程上的分配器
- Fast Thread Shared Temporary Allocators:线程间共享的临时分配器
- Profiler Allocators:用于profiler使用的分配器
按底层类型分类
- UnityDefaultAllocator
- BucketAllocator
- DynamicHeapAllocator
- DualThreadAllocator
- TLSAllocator(Thread Local Storage)
- StackAllocator
- ThreadSafeLinearAllocator
- …
Unity中的内存分配器
| 分配器类型 | 分配器算法 | 用途 |
|---|---|---|
| Bucket 桶分配器 | Two Level Segregated Fit(TLSF) | - Main allocator - Gfx allocator - Typetree allocator - File cache allocator - Profiler allocator - Editor Profiler allocator (on Editor only) |
| Dynamic Heap动态堆分配器 | Fixed size lock-free allocator | As a shared allocator for small allocations for: - Main allocator - Gfx allocator - Typetree allocator - File cache allocator |
| Dual thread | Redirects allocations based on size and thread ID | - Main allocator - Gfx allocator - Typetree allocator - File cache allocator |
| Thread Local Storage(TLS) stack | LIFO stack | Temporary allocations |
| Threadsafe linear | Round robin FIFO | Buffers for passing data to jobs |
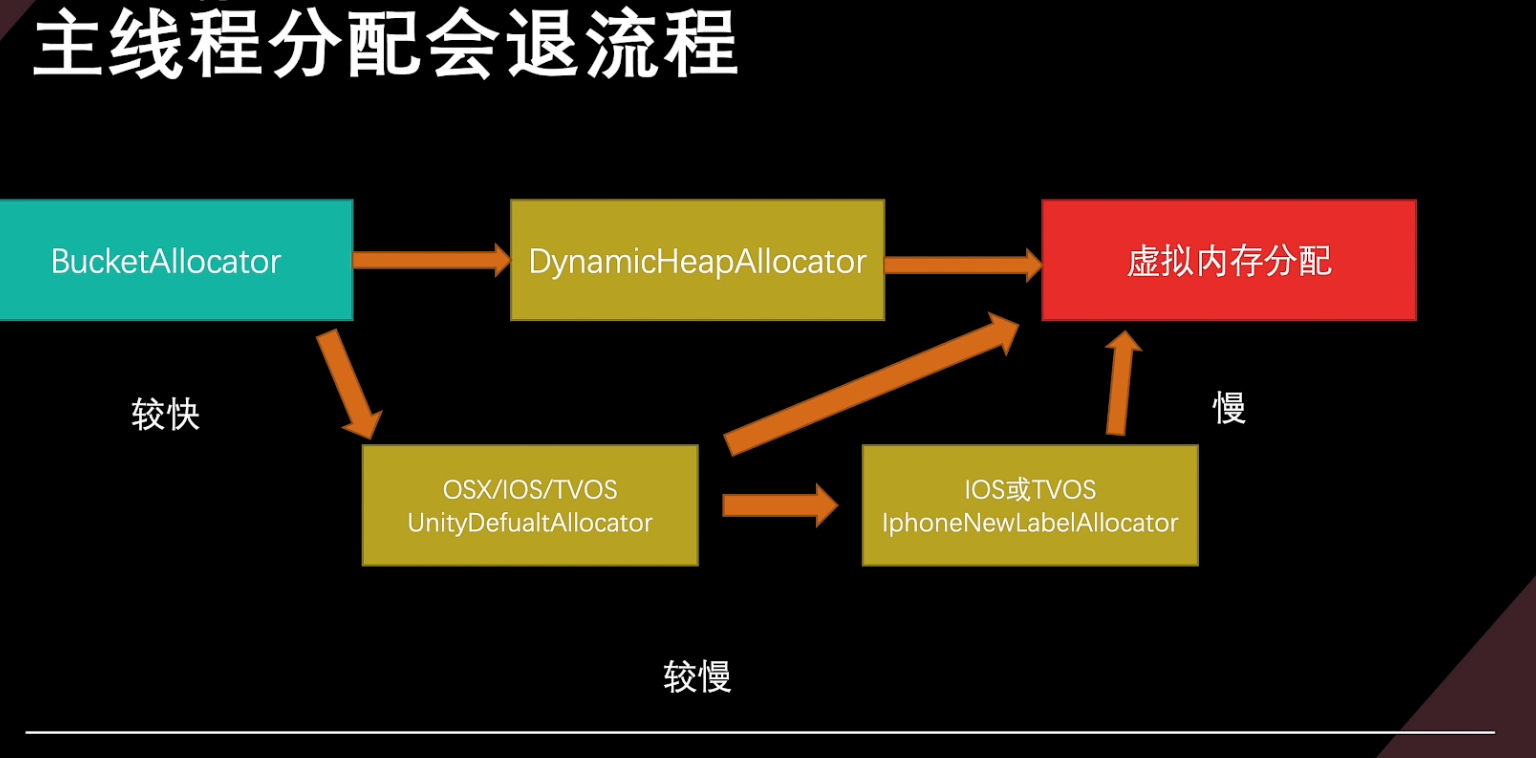
BucketAllocator(桶分配器)
- 每个bucket由固定大小粒度granularity表示,如果granularity为16字节大小,则用于分配
16/32/48/54/…字节的内存,如果是development版本granularity在设置大小的基础上增加40个
字节 - 分配器为分配保留内存块Block,每个块被划分为16kb的子段(subsections),并且不可配置。
Block块只能增长,并且需要是固定16kb大小的整数倍。 - 分配是固定大小无锁的,速度快,通常作为进入堆分配器之前用来加速小内存分配的分配器
- Log日志中可以通过查看[ALLOC_BUCKET]字段来看是否有Failed Allocations. Bucket layout字段,以及Peak Allocated bytes字段与Large Block size字段的利用率,来判定大小是否分配合适,
- 分配失败会会退到DynamicHleapAllocator或UnityDefaultAllocator分配器上,效率变差。
DynamicHeapAllocator(动态堆分配器)
- 所有平合都希望使用的分配器 (Mac与iOS哲时仍然使用Unity DefaultAllocator,可以理解为原生的alloc和free)
- 底层基于TLSF,保留tsf块列表,并在一个块已满后,切换到另一个块,或没有时分配一个新块,关
于TLSF :http://www.gii.upv.es/tlsf/files/ecrts04_tlsf.pdf - 最棘手的部分是设置块的大小。根据不同平合,更大的块效率更高,碎片更少,但对于内存有限的平台来说灵活性差
- 最大块为256M,最小块为128k,如果64位架构使用更大的Reaion来保存多个块
MEMORY_USE_LARGE_BLOCKS,如果分配失败会会退到虛拟内存分配,效率更差 - Log中[ALLOC_DEFAULT_MAIN]下关注Peak usage frame count字段,查看大多数帧分配内存的范圃,关注内存分配峰值Peak Allocated memory字段,以区Peak Large allocation bytes没有使用TLSF分配的内存大小
DualThreadAllocator
- 它是将2个DynamicHeapAllocator实例与1个BucketAllocator封装到一起,其中BucketAllocator负责小的共享内存分配,1个无锁的DynamicHeapAllocator用于主线程分配,另外一个DynamicHleapAllocator负责其他线程的共享分配,但是分配与回收时需要加锁
- Log中[ALLOC_DEFAULT]下分别关注[ALLOC_BUCKET]、[ALLOC_DEFAULT_MAIN]、[ALLOC_DEFAULT_THREAD]字段下一个BucketAllocator与2个DynamicHeapAllocator的分配信息,其中尤其关注Peak main deferred allocation count字段,这个字段代表需要在主线程回收的分配队列。
- 负责其他线程的共享分配的DynamicHeapAllocatord对应C#非托管内存的Allocator.Persistent
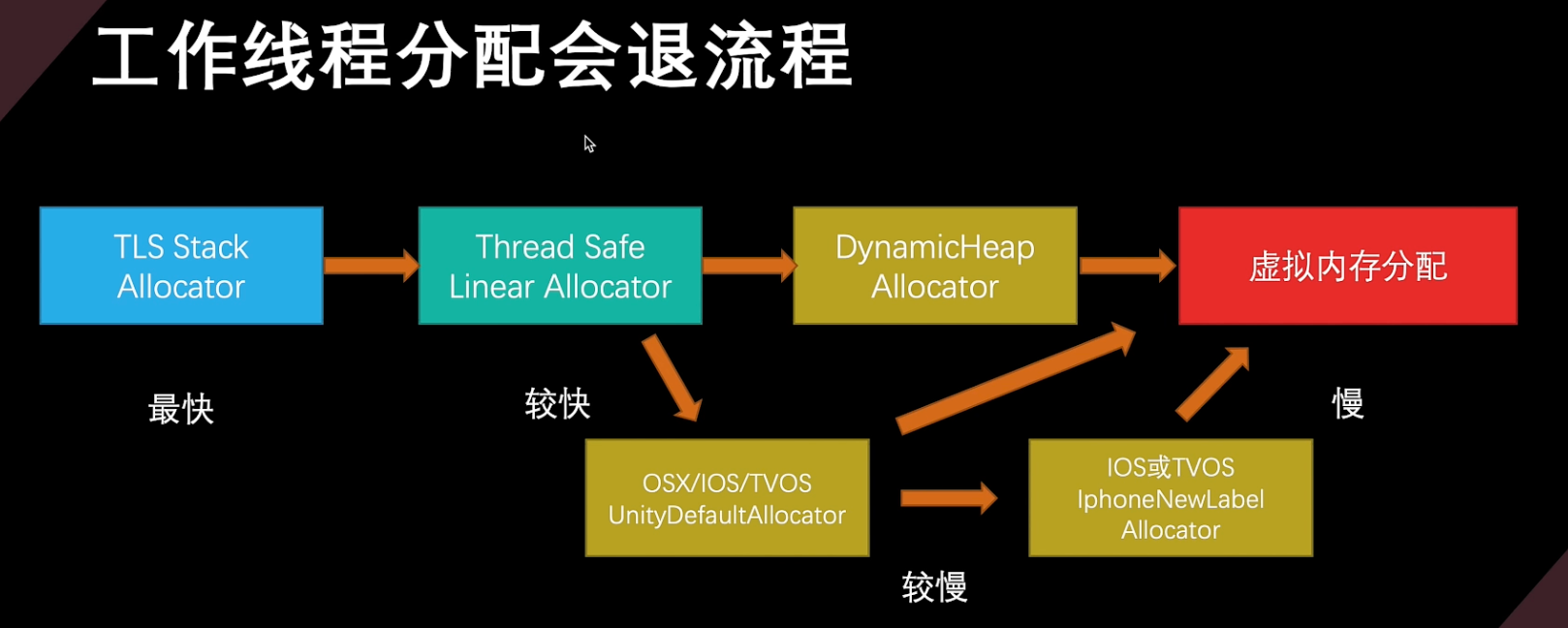
TLS Stack Allocator
- 用于快速临时分配的堆栈分配器。它是最快的分配器,几乎没有开销,并且可以防止内存碎片,对应C#非托管内存的Allocator.Temp分配类型
- 它是基于后进先出LIFO的算法,分配的内存生命周期在一帧内。
- 如果分配器使用超过了配置的大小,Unity会增加分配块大小,但会是配置设置的2倍大小,
- 如果线程堆栈分配器满了,分配器将会退到线程安全线性job分配器。这时一帧内允许有1-10分配,甚至如果是加载期间可以允许几百次。但如果每帧的分配数字增加可以考虑增加块大小。
- Log日志[ALLOC_TEMP_TLSJ下关注[ALLOC TEMP_MAIN]与[ALLOC TEMP Job.Worker xx]中的Peak usage frame count于Peak Allocated Bytes字段,也要关注Overtlow Count字段,是否发生了分配器溢出回退的情況。
Thread Safe Linear Allocator
- 用于快速无锁分配Job线程的缓冲区,并在Job完成后释放缓冲区,对应C#非托管内存的Allocator.TempJob
- 采用循环先进先出FIFO算法,先分配内存块,然后在这些内存块内进行线性分配内存所有可用块都会存到一个池中,当一个块满时再从池中提取一个新的可用块。当分配器不再需要块中内存时,清理该块并放回到可用池中。快速清理分配可用块非常重要。因此Job的分配尽量在几帧内完成。
- 如果所有块都在使用中,或者一个分配对于一个块太大的情况下,则会退到主堆分配
器,分配效率会下降。 - Log日志[ALLOC_ TEMP_ JOB_4_FRAMESJ中我们需要关注Overflow Cout(too large)与Overtlow Count(full)字段,判断是否发生了分配器溢出会退。
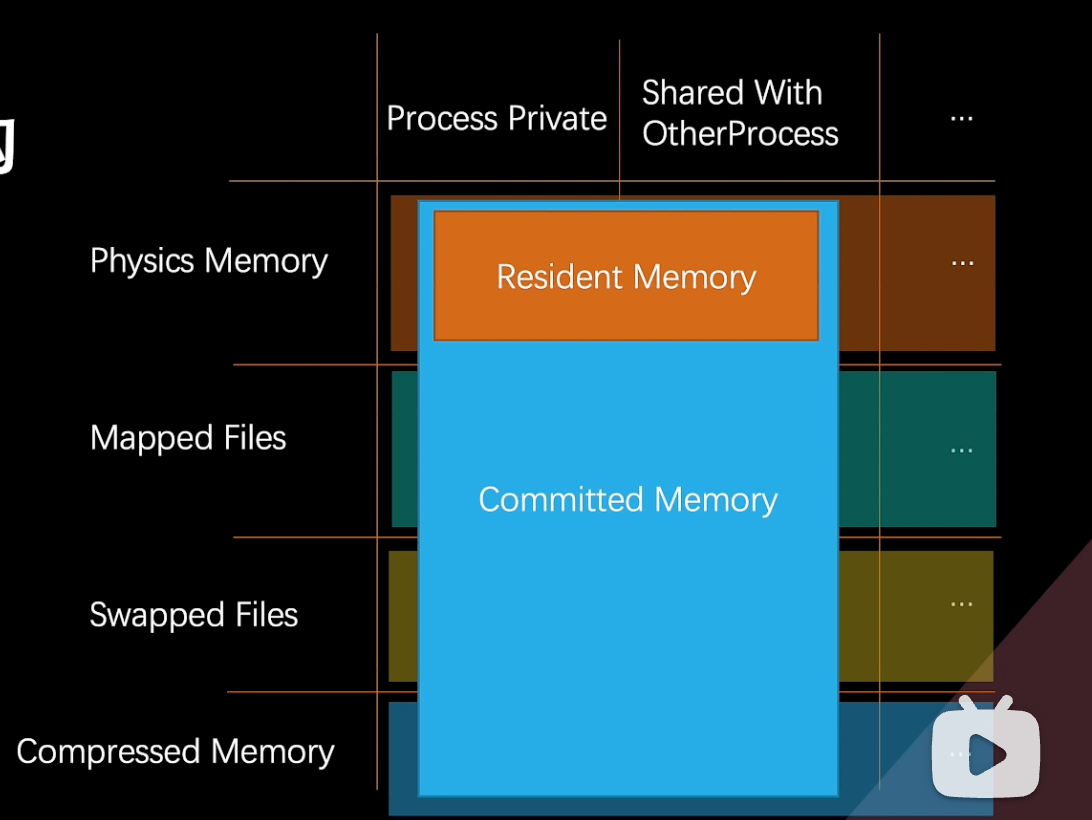
内存指标术语与进程内存结构
Memory Profiler中的内存度量与术语
- Page操作系统内存管理的最小单元(通常是4KB大小,但不同操作系统和平台会有所不同)
- 内存管理单元MMU,维护一张Page的表,将虚拟地址映射到物理内存地址上。
- 当用户访问虚拟地址时,会自动被MMU转换到物理内存地址,但如果CPU没有找到虚拟地址映射的物理内存地址时,会触发page fault中断当前程序执行,然后再分配一块干净的物理内存,并从磁盘加载所需的一页数据到该物理地址,同时更新页表,继续执行
- 一个进程向系统申请内存时,并不会返回物理内存地址,而是返回虚拟内存地址,仅当CPU需要访问该虚拟地址时,系统才会分配并映射到物理内存上
- Page的状态
- Used,Page正在被进程使用,内存页也映射到物理内存中
- Free,该page可用,且内存页还没有被映射到物理内存中
- Cache,该Page被操作系统用于缓存的可用内存,虽然内存页已经被映射到物理内存中,但该Page可能近期没有被访问,如果Free page低于阈值时,操作系统会从Cache去获取内存,并将Cache页数据交换到磁盘,然后对Cache页进行清理,标记为Free Cache
- Region,将Page组织成区域,是一块共享内存状态和保护级别的连续地址空间,可以由具有不同page状态的多个页面组成
- Region的状态
- Resident:其中的配置页已经在物理内存中
- Dirty:配置已修改,但未写入磁盘
- Wired:代表永远不会交换到辅助存储的固定配置段
- Committed:代表已分配的内存区域,其地址不能被其他分配使用,是由RAM、磁盘上的分页文件或其他资源来支持的,访问权限由内存的保护级别控制
- Reserved:保留地址空间供将来使用,地址不会被其他分配使用,也不可访问,没有与之关联的物理存储
- Free:空闲内存区域,既不会Committed也不会Reserved,进程无法访问
- Region的类型
- Anonymous:与文件系统的文件并无关联,如c++使用malloc的任何分配
- Mapped:与文件系统、设备节点相关联,直接映射
进程的内存结构
- USS :当前进程私有的Resident内存总和
- PSS :当前进程常驻内存与其他进程共享的Resident内存总和
- RSS :进程可访问的Resident常驻内存总和
- VSS : 总共Committed提交的Region内存总和
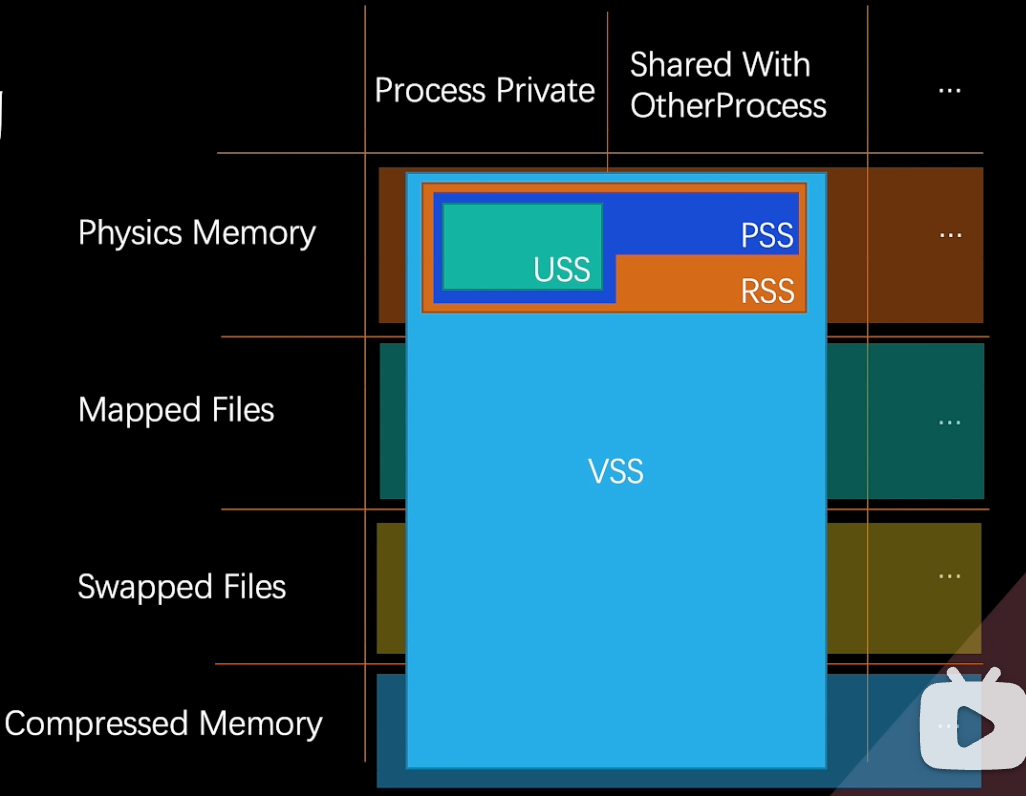
各工具的内存指标
- Unity Memory Profiler是对VSS进行衡量的
- Windows资源管理器的内存指标是针对USS衡量
- Xcode上内存指标是RSS+压缩后内存交换页的大小
移动平台内存经验值数据分享
- Texture: 80M-160M
- Mesh: 50M-70M
- Render Texture: 50-80M
- AnimationClips: 30-60M
- Audio: 10-20M
- Cubemap: 0-50M
- Font: 5M-15M
- Shader: 20M-40M(小心shader变体,看这篇https://blog.unity.com/engine-platform/stripping-scriptable-shader-variants)
- System.xxx 总和:15M-30M(不要将大的配置表缓存进内存,特别是文本数据)
- AssetBundle: 0-10M
- 其他各类对象单项:0-10M,数量小于10000
- ReservedMono: <100M
- ReservedGFX: <300M
- ReservedTotal: <650M
主要优化手段
- 导入资源优化设置
- 如果Mesh占用的内存过高,就要考虑Static Batching使用是否划算了,可以在player setting中一键关闭
- 如果使用了Terrain烘焙Mesh的方案,会造成顶点数和内存增高,考虑是否需要烘焙的优化方案
- RT纹理需要去除冗余资源,以及分辨率调整
- HDR纹理占用内存会增多一半左右
- Texture2d纹理可以强制控制(Texture Quality)某个平台使用某一级别以及以下级别的mipmap纹理,但这个需要运行前确认,适用于高中低机型调整
- 利用Mipmap Streaming功能可以运行时动态调整mipmap层级,使用少量cpu资源来降低GPU显存使用
- 使用Streaming Controller脚本控制相机的mipmap bias偏移
- Unity关于Mipmap Streaming的示例项目+UI调试项目 https://github.com/lwwhb/MipMapStreamingDemo
- 使用Editor.log查看打包shader 变体情况(剔除与收集),2022有dynamic_branch关键字,不会产生变体的分支
- 托管内存优化技巧与建议
- Boxing Allocation装箱操作
- 使用lua和unity交互时,尽量不要传递unity内存对象,而是传递或返回基础类型值对象,lua内存查看:https://github.com/leinlin/Miku-LuaProfiler
- Stringt字符串拼接
- 闭包分配
- 避免使用Linq库,会生成大量托管堆垃圾内存
- Unity中提供了NonAlloc函数,如Physics.RayCastAll用Physics.RayCastAlINonAlloc代替
- 有托管内存开销:Unity.Object.FindObjectsOfType、UnityEngine.Component.GetComponentsInParent、UnityEngine.Component.GetComponentslnChild 等
- 成员变量访问方式
- UnityEngine.Mesh.vertices=> UnityEngine.Mesh.GetVertices,
- UnityEngine.Mesh.uv=> UnityEngine.Mesh.GetUV
- UnityEngine.Renderer.sharedMaterials=>UnityEngine.Renderer.GetSharedMaterials,
- Unity.lnput.touches=>Unity.lnput.GeTouches等
- 程序集优化:Strip Engine Code

kio0o0
如果可以做到不懂就问,做不到的事情就拒绝,或许可以活得更轻松点